The tick-data provided in the .csv (comma separated values) file format sometimes may be a real problem to handle quickly, especially when the total size starts to count in hundreds of GB. If your goal is data extraction for time-series with, say, hourly time resolution only, this article will provide you with some fresh and constructive guidelines how to do it smartly in the Linux environment.
Initial Preprocessing
First, let’s have a closer look at the data. Say, we have a collection of 2148 .csv files hosting the FX trading history of AUDUSD pair, covering nearly 10 years between 2000 and 2010. Each file is 7.1 MB large what leaves us with approximately 15 GB of data to process. Having a look into the randomly selected file we can identify the header and data themselves:
$ head -10 audusd_216.csv Ticks,TimeStamp,Bid Price,Bid Size,Ask Price,Ask Size 632258349000000015,2004-07-19 11:55:00.000,0.7329,1000000,0.7334,1000000 632258349000000016,2004-07-19 11:55:00.000,0.7329,1000000,0.7334,1000000 632258349000000017,2004-07-19 11:55:00.000,0.7329,1000000,0.7333,1000000 632258349000000018,2004-07-19 11:55:00.000,0.7327,1000000,0.7333,1000000 632258349000000019,2004-07-19 11:55:00.000,0.7327,1000000,0.7333,1000000 632258349000000020,2004-07-19 11:55:00.000,0.7328,1000000,0.7333,1000000 632258349000000021,2004-07-19 11:55:00.000,0.7328,1000000,0.7334,1000000 632258349600000000,2004-07-19 11:56:00.000,0.7328,1000000,0.7334,1000000 632258349600000001,2004-07-19 11:56:00.000,0.7328,1000000,0.7336,1000000
Our aim will be to extract Bid and Ask Price time-series. We will make use of a few Linux standard tools, e.g. sed, awk, supplemented with extra f77 codes. It is also to demonstrate how shell programming can be useful while we have an opportunity to explore the enigmatic syntax of its programs. Generally, we will be writing a shell script, executable for any FX pair name, e.g. gbpnzd, eurjpy, and so on.
In the first step of the script we create a list of all files. This is tricky in Linux as the standard command of ‘ls -lotr’ though returns a desired list but also all details on the file size, attributes, etc. which we do not simply want. Lines 9 and 10 solve the problem,
# Extracting Time-Series from Tick-Data .csv files
# (c) Quant at Risk, 2012
#
# Exemplary usage: ./script.src audusd
#!/bin/bash
echo "..making a sorted list of .csv files"
for i in $1_*.csv; do echo ${i##$1_} $i ${i##.csv};
done | sort -n | awk '{print $2}' > $1.lst
and a newly create file of \$1.lst (note: \$1 corresponds in the shell script to the parameter’s name we called the script with, e.g. audusd; therefore \$1.lst physically means audusd.lst) contains the list:
audusd_1.csv audusd_2.csv audusd_3.csv ... audusd_2148.csv
We create one data file from all 2148 pieces by creating and executing an in-line script:
echo "..creating one data file"
awk '{print "cat",$1," >> tmp.lst"}' $1.lst > tmp.cmd
chmod +x tmp.cmd
./tmp.cmd
rm tmp.cmd
mv tmp.lst $1.tmp
Now, \$1.tmp is a 15 GB file and we may wish to remove some unnecessary comments and tokens:
echo "..removing comments"
sed 's/Ticks,TimeStamp,Bid Price,Bid Size,Ask Price,Ask Size//g' $1.tmp > $1.tmp2
rm $1.tmp
echo "..removing empty lines"
sed '/^$/d' $1.tmp2 > $1.tmp
rm $1.tmp2
echo "..removing token ,"
sed 's/,/ /g' $1.tmp > $1.tmp2
rm $1.tmp
echo "..removing token :"
sed 's/:/ /g' $1.tmp2 > $1.tmp
rm $1.tmp2
echo "..removing token -"
sed 's/-/ /g' $1.tmp > $1.tmp2
rm $1.tmp
echo "..removing column with ticks and ask/bid size"
awk '{print $2,$3,$4,$5,$6,$7,$8,$10}' $1.tmp2 > $1.tmp
rm $1.tmp2
In order to convert a time information into a Continuous Measure of Time, we modify the f77 Fortran code for our task as follows:
c Extracting Time-Series from Tick-Data .csv files
c (c) Quant at Risk, 2012
c
c Program name: fx_getmjd.for
c Aim: removes ticks and coverts trade time into MJD time [day]
c Input data format: YYYY MM DD HH MM SS.SSS BID BID_Vol ASK ASK_Vol
implicit double precision (a-z)
integer y,m,d,hh,mm,jd
integer*8 bidv,askv
character zb*50
call getarg(1,zb)
open(1,file=zb)
do i=1.d0, 500.d6
read(1,*,end=1) y,m,d,hh,mm,ss,bid,ask
jd= d-32075+1461*(y+4800+(m-14)/12)/4+367*(m-2-(m-14)/12*12)
_ /12-3*((y+4900+(m-14)/12)/100)/4
mjd=(jd+(hh-12.d0)/24.d0+mm/1440.d0+ss/86400.d0)-2400000.5d0
mjd=mjd-51544.d0 ! T_0 = 2000.01.01 00:00
abr=ask/bid
write(*,2) mjd,bid,ask,abr
enddo
1 close(1)
2 format(F15.8,F8.4,F8.4,F12.6)
end
and execute it in our script:
echo "..changing a date to MJD" fx_getmjd $1.tmp > $1.dat rm $1.tmp
In the aforementioned f77 code, we set a zero time point (MJD=0.00) on Jan 1, 2000 00:00. Since that day, now our time is expressed as a single column measuring time progress in days with fractional parts tracking hours and minutes.
We may split the data into two separate time-series containing Bid and Ask Prices at the tick-data level:
echo "..splitting into bid/ask/abr files"
awk '{print $1,$2}' $1.dat > $1.bid
awk '{print $1,$3}' $1.dat > $1.ask
A quick inspection of both files reveals we deal with nearly $500\times 10^6$ lines! Before we reach our chief aim, i.e. rebinning the series with 1-hour time resolution, there is a need to, unfortunately, separate input into 5 parts, each of maximum $100\times 10^6$ lines. The latter may vary depending of RAM memory size available, and if sufficient, this step can be even skipped. We proceed:
echo "..spliting bid/ask/abr into separate files" fx_splitdat $1 1 fx_splitdat $1 2 fx_splitdat $1 3 fx_splitdat $1 4 fx_splitdat $1 5
where fx_splitdat.for code is given as follows:
c Extracting Time-Series from Tick-Data .csv files
c (c) Quant at Risk, 2012
c
c Program name: fx_splitdat.for
c Exemplary usage: ./fx_splitdat audusd [1,2,3,4,5]
implicit double precision (a-z)
integer nc
character*6 zb
character*10 zbask,zbbid
character*16 zb1ask,zb2ask,zb3ask,zb4ask,zb5ask
character*16 zb1bid,zb2bid,zb3bid,zb4bid,zb5bid
character*1 par2,st
c zb- name of length equal 6 characters only
call getarg(1,zb)
call getarg(2,par2) ! case
write(st,'(a1)') par2
read(st,'(i1)') nc
zbask=zb(1:6)//'.ask'
zbbid=zb(1:6)//'.bid'
zb1ask=zb(1:6)//'.ask.part1'
zb2ask=zb(1:6)//'.ask.part2'
zb3ask=zb(1:6)//'.ask.part3'
zb4ask=zb(1:6)//'.ask.part4'
zb5ask=zb(1:6)//'.ask.part5'
zb1bid=zb(1:6)//'.bid.part1'
zb2bid=zb(1:6)//'.bid.part2'
zb3bid=zb(1:6)//'.bid.part3'
zb4bid=zb(1:6)//'.bid.part4'
zb5bid=zb(1:6)//'.bid.part5'
open(11,file=zbask)
open(12,file=zbbid)
if(nc.eq.1) then
open(21,file=zb1ask)
open(22,file=zb1bid)
do i=1.d0, 100.d6
read(11,*,end=1) mjd_ask,dat_ask
read(12,*,end=1) mjd_bid,dat_bid
if((i>=1.0).and.(i<100000001.d0)) then
write(21,2) mjd_ask,dat_ask
write(22,2) mjd_bid,dat_bid
endif
enddo
endif
if(nc.eq.2) then
open(31,file=zb2ask)
open(32,file=zb2bid)
do i=1.d0, 200.d6
read(11,*,end=1) mjd_ask,dat_ask
read(12,*,end=1) mjd_bid,dat_bid
if((i>=100000001.d0).and.(i<200000001.d0)) then
write(31,2) mjd_ask,dat_ask
write(32,2) mjd_bid,dat_bid
endif
enddo
endif
if(nc.eq.3) then
open(41,file=zb3ask)
open(42,file=zb3bid)
do i=1.d0, 300.d6
read(11,*,end=1) mjd_ask,dat_ask
read(12,*,end=1) mjd_bid,dat_bid
if((i>=200000001.d0).and.(i<300000001.d0)) then
write(41,2) mjd_ask,dat_ask
write(42,2) mjd_bid,dat_bid
endif
enddo
endif
if(nc.eq.4) then
open(51,file=zb4ask)
open(52,file=zb4bid)
do i=1.d0, 400.d6
read(11,*,end=1) mjd_ask,dat_ask
read(12,*,end=1) mjd_bid,dat_bid
if((i>=300000001.d0).and.(i<400000001.d0)) then
write(51,2) mjd_ask,dat_ask
write(52,2) mjd_bid,dat_bid
endif
enddo
endif
if(nc.eq.5) then
open(61,file=zb5ask)
open(62,file=zb5bid)
do i=1.d0, 500.d6
read(11,*,end=1) mjd_ask,dat_ask
read(12,*,end=1) mjd_bid,dat_bid
if((i>=400000001.d0).and.(i<500000001.d0)) then
write(61,2) mjd_ask,dat_ask
write(62,2) mjd_bid,dat_bid
endif
enddo
endif
1 close(1)
2 format(F15.8,F8.4)
stop
end
and compiling it as usual:
f77 fx_splitdat.for -o fx_splitdat
Data Extraction
Finally, we can extract the rebinned Bid and Ask Price time-series with bin time of 1 hour, i.e. $dt=0.041666667$ d, making use of the following f77 code:
c Extracting Time-Series from Tick-Data .csv files
c (c) Quant at Risk, 2012
c
c Program name: fx_rebin.for
c Exemplary usage: ./fx_rebin audusd 2
implicit double precision (a-z)
parameter (dim=100.d6)
double precision f(dim), mjd(dim), step
character*50 par1, par2, st
call getarg(1,par1) ! file name
call getarg(2,par2) ! bining [d]
write(st,'(a20)') par2
read(st,'(f20)') step
c reading data
open(1,file=par1)
do i=1,100.d6
read(1,*,end=1)
_ mjd(i),f(i)
enddo
1 close(1)
n=i-1.d0
c main loop
j=1.d0
k=1.d0
t2=0.
t2=dint(mjd(j))
do while (j.lt.n)
i=j
if ((mjd(i)+step).gt.(mjd(n))) then
print*
stop
else
t2=t2+step
endif
i=j
il=0.d0
s=0.d0
do while (mjd(i).lt.t2)
s=s+f(i)
i=i+1.d0
il=il+1.d0 ! how many points in segment
enddo
av=s/il
day=t2-step
if (il.ge.1.d0) then
write(*,3) day,av
endif
j=j+il
enddo
2 format(f30.7,2f30.6)
3 format(f20.8,f8.4)
10 stop
end
executed in our script for all five part of both tick-data time-series:
echo "..rebinning with dt = 1 h" dt=0.041666667 fx_rebin $1.ask.part1 $dt > $1.ask.part1.1h fx_rebin $1.ask.part2 $dt > $1.ask.part2.1h fx_rebin $1.ask.part3 $dt > $1.ask.part3.1h fx_rebin $1.ask.part4 $dt > $1.ask.part4.1h fx_rebin $1.ask.part5 $dt > $1.ask.part5.1h fx_rebin $1.bid.part1 $dt > $1.bid.part1.1h fx_rebin $1.bid.part2 $dt > $1.bid.part2.1h fx_rebin $1.bid.part3 $dt > $1.bid.part3.1h fx_rebin $1.bid.part4 $dt > $1.bid.part4.1h fx_rebin $1.bid.part5 $dt > $1.bid.part5.1h echo "..appending rebinned files" cat $1.ask.part1.1h $1.ask.part2.1h $1.ask.part3.1h $1.ask.part4.1h $1.ask.part5.1h >$1.ask.1h.tmp cat $1.bid.part1.1h $1.bid.part2.1h $1.bid.part3.1h $1.bid.part4.1h $1.bid.part5.1h > $1.bid.1h.tmp rm *part* echo "..removing empty lines in rebinned files" sed '/^$/d' $1.ask.1h.tmp > $1.ask.1h rm $1.ask.1h.tmp sed '/^$/d' $1.bid.1h.tmp > $1.bid.1h rm $1.bid.1h.tmp echo "..done!"
As the final product we obtain two files, say,
audusd.bid.1h audusd.ask.1h
of the content:
$ tail -5 audusd.bid.1h
3772.62500304 0.9304
3772.66666970 0.9283
3772.70833637 0.9266
3772.75000304 0.9263
3772.79166970 0.9253
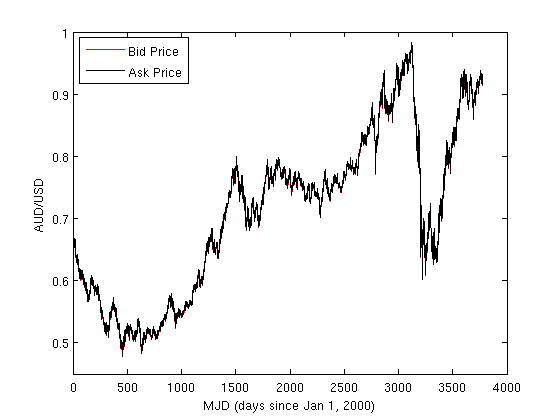
where the first column is time (MJD) with 1-hour resoulution and the second column contains a simple Price average from all tick prices falling into 1-hour time bin. As for dessert, we plot both Bid and Ask Price time-series what accomplishes our efforts:
Dive Deeper
Rebinning Tick-Data for FX Algo Traders